Note
Go to the end to download the full example code.
Acoustic Human Pose estimation Tutorial¶
!pip install pysensing
In this tutorial, we will be implementing codes for acoustic Human pose estimation
from pysensing.acoustic.datasets.utils.hpe_vis import *
from pysensing.acoustic.models.hpe import Speech2pose,Wipose_LSTM
from pysensing.acoustic.models.get_model import load_hpe_model
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
- Listening Human Behavior: 3D Human Pose Estimation with Acoustic Signals
Implementation of “Listening Human Behavior: 3D Human Pose Estimation with Acoustic Signals”.
This dataset contains the audio reflected by human to estimate the 3D human pose with the acoustic signals.
Reference: https://github.com/YutoShibata07/AcousticPose_Public
Load the data¶
# Method 1: Use get_dataloader
from pysensing.acoustic.datasets.get_dataloader import *
train_loader,val_loader,test_loader = load_hpe_dataset(
root='./data',
dataset_name='pose_regression_timeseries_subject_1',
download=True)
# Method 2
csv = './data/hpe_dataset/csv/pose_regression_timeseries_subject_1/test.csv' # The path contains the samosa dataset
data_dir = './data'
hpe_testdataset = SoundPose2DDataset(csv,sound_length=2400,input_feature='logmel',
mean=np.array(get_mean()).astype("float32")[:4],
std=np.array(get_std()).astype("float32")[:4],
)
index = 10 # Randomly select an index
sample= hpe_testdataset.__getitem__(index)
print(sample['targets'].shape)
print(sample['sound'].shape)
torch.Size([12, 63])
torch.Size([4, 12, 128])
Load Speech2pose model¶
# Method 1
hpe_model = Speech2pose(out_cha=63).to(device)
# model_path = 'path to pretrian weights'
# state_dict = torch.load(model_path,weights_only=True)
# hpe_model.load_state_dict(state_dict)
# Method 2
hpe_model = load_hpe_model('speech2pose',pretrained=True,task='subject8').to(device)
Modle Inference¶
#Method 1
sample= hpe_testdataset.__getitem__(index)
hpe_model.eval()
predicted_result = hpe_model(sample['sound'].unsqueeze(0).float().to(device))
vis_images = make_images(sample['targets'].numpy(),predicted_result.cpu().detach().numpy().squeeze(0))
#Method 2
from pysensing.acoustic.inference.predict import *
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
predicted_result = hpe_predict(sample['sound'],'SoundPose2DDataset',hpe_model, device=device)
vis_images = make_images(sample['targets'].numpy(),predicted_result.cpu().detach().numpy().squeeze(0))
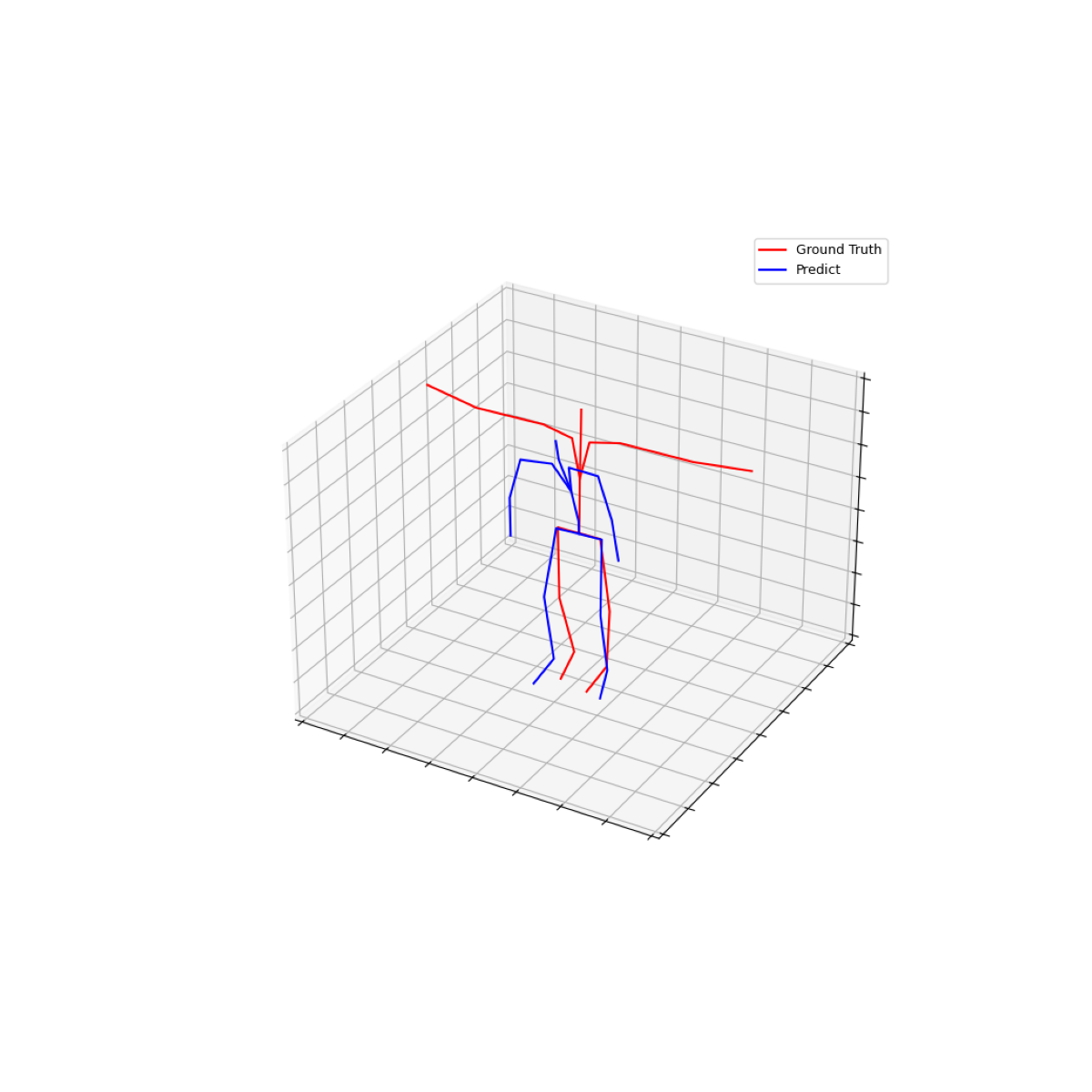
seq_num = 0
fig = plt.figure(figsize=(12, 12))
plt.imshow(vis_images[seq_num]['img'])
plt.axis('off')
plt.show()
/home/kemove/anaconda3/envs/il/lib/python3.9/site-packages/torch/nn/modules/conv.py:306: UserWarning: Using padding='same' with even kernel lengths and odd dilation may require a zero-padded copy of the input be created (Triggered internally at ../aten/src/ATen/native/Convolution.cpp:1008.)
return F.conv1d(input, weight, bias, self.stride,
Modle Embedding¶
from pysensing.acoustic.inference.embedding import *
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
sample_embedding = hpe_embedding(sample['sound'],'SoundPose2DDataset',hpe_model, device=device)
Modle Training¶
from pysensing.acoustic.inference.training.AcousticPose_utils.hpe_train import train_model,generate_configs
args = {
"root_dir": "./data/hpe_dataset/testing_result",
"save_name": "seq1",
"input_feature": "logmel",
"batchsize": 64,
"max_epoch": 50,
"csv_path": "./data/hpe_dataset/csv",
"dataset_name": "pose_regression_timeseries_subject_1",
"model": "speech2pose",
"sound_length": 2400,
"learning_rate": 0.01,
}
config_path = args["root_dir"]+'/'+args["save_name"]+"/config.yaml"
generate_configs(args)
resume_training = False
random_seed = 0
train_model(
config_path=config_path,
resume=resume_training,
seed=random_seed,
)
# Modle Training
# ------------------------
from pysensing.acoustic.inference.training.AcousticPose_utils.hpe_test import evaluate_model
args = {
"root_dir": "./data/hpe_dataset/testing_result",
"save_name": "seq1",
"batchsize": 64,
"max_epoch": 20,
"csv_path": "./data/hpe_dataset/csv",
"dataset_name": "pose_regression_timeseries_subject_1",
"model": "speech2pose",
"sound_length": 2400,
"learning_rate": 0.01,
}
config_path = args["root_dir"]+'/'+args["save_name"]+"/config.yaml"
evaluation_mode = "test"
model_path = None
evaluate_model(
config_path=config_path,
mode=evaluation_mode,
model_path=model_path)
{'csv_path': './data/hpe_dataset/csv', 'model': 'speech2pose', 'pretrained': True, 'use_class_weight': True, 'batch_size': 32, 'width': 224, 'height': 224, 'num_workers': 8, 'max_epoch': 50, 'learning_rate': 0.01, 'sound_length': 2400, 'dataset_name': 'pose_regression_timeseries_subject_1', 'input_feature': 'logmel', 'topk': (1, 3), 'smooth_loss': False, 'ratio': 0.0, 'gan': 'none', 'finetune': 0, 'aug': 'none'}
Finished making configuration files.
/home/kemove/anaconda3/envs/il/lib/python3.9/site-packages/pysensing/acoustic/inference/training/AcousticPose_utils/libs/dataset.py:195: FutureWarning: DataFrame.fillna with 'method' is deprecated and will raise in a future version. Use obj.ffill() or obj.bfill() instead.
self.df[self.df["sound_length"] == sound_length]
/home/kemove/anaconda3/envs/il/lib/python3.9/site-packages/pysensing/acoustic/inference/training/AcousticPose_utils/libs/dataset.py:195: FutureWarning: DataFrame.fillna with 'method' is deprecated and will raise in a future version. Use obj.ffill() or obj.bfill() instead.
self.df[self.df["sound_length"] == sound_length]
epoch: 0 epoch time[sec]: 4 train loss: 38.0937 val loss: 163.1282 val_rmse: 12.77217 val_mae: 8.43311
epoch: 1 epoch time[sec]: 1 train loss: 3.3102 val loss: 50.4458 val_rmse: 7.10252 val_mae: 4.40765
epoch: 2 epoch time[sec]: 1 train loss: 1.5292 val loss: 1.8193 val_rmse: 1.34880 val_mae: 0.82698
epoch: 3 epoch time[sec]: 1 train loss: 1.1860 val loss: 1.4522 val_rmse: 1.20507 val_mae: 0.72901
epoch: 4 epoch time[sec]: 1 train loss: 1.0476 val loss: 1.2415 val_rmse: 1.11424 val_mae: 0.64408
epoch: 5 epoch time[sec]: 1 train loss: 0.8655 val loss: 1.5326 val_rmse: 1.23800 val_mae: 0.72606
epoch: 6 epoch time[sec]: 1 train loss: 0.8991 val loss: 1.7280 val_rmse: 1.31454 val_mae: 0.75788
epoch: 7 epoch time[sec]: 1 train loss: 0.7731 val loss: 1.4055 val_rmse: 1.18552 val_mae: 0.67471
epoch: 8 epoch time[sec]: 1 train loss: 1.0249 val loss: 33.7593 val_rmse: 5.81028 val_mae: 3.50439
epoch: 9 epoch time[sec]: 1 train loss: 0.8726 val loss: 3.8771 val_rmse: 1.96904 val_mae: 1.12149
epoch: 10 epoch time[sec]: 1 train loss: 0.7102 val loss: 1.1204 val_rmse: 1.05849 val_mae: 0.56559
epoch: 11 epoch time[sec]: 1 train loss: 0.5611 val loss: 1.5317 val_rmse: 1.23764 val_mae: 0.69886
epoch: 12 epoch time[sec]: 1 train loss: 0.5923 val loss: 3.0224 val_rmse: 1.73850 val_mae: 1.06073
epoch: 13 epoch time[sec]: 1 train loss: 0.5095 val loss: 3.3477 val_rmse: 1.82968 val_mae: 1.13779
epoch: 14 epoch time[sec]: 1 train loss: 0.6626 val loss: 2.4439 val_rmse: 1.56328 val_mae: 0.91174
epoch: 15 epoch time[sec]: 1 train loss: 0.5039 val loss: 1.3499 val_rmse: 1.16187 val_mae: 0.62304
epoch: 16 epoch time[sec]: 1 train loss: 0.4427 val loss: 0.8582 val_rmse: 0.92637 val_mae: 0.49949
epoch: 17 epoch time[sec]: 1 train loss: 0.4141 val loss: 0.7087 val_rmse: 0.84182 val_mae: 0.44726
epoch: 18 epoch time[sec]: 1 train loss: 0.4481 val loss: 1.9027 val_rmse: 1.37937 val_mae: 0.81386
epoch: 19 epoch time[sec]: 1 train loss: 0.4947 val loss: 0.7230 val_rmse: 0.85029 val_mae: 0.46919
epoch: 20 epoch time[sec]: 1 train loss: 0.4163 val loss: 0.7290 val_rmse: 0.85384 val_mae: 0.46518
epoch: 21 epoch time[sec]: 1 train loss: 0.3556 val loss: 0.4851 val_rmse: 0.69652 val_mae: 0.38136
epoch: 22 epoch time[sec]: 1 train loss: 0.3800 val loss: 0.5969 val_rmse: 0.77261 val_mae: 0.41563
epoch: 23 epoch time[sec]: 1 train loss: 0.3724 val loss: 0.6957 val_rmse: 0.83409 val_mae: 0.47226
epoch: 24 epoch time[sec]: 1 train loss: 0.3783 val loss: 0.7569 val_rmse: 0.87001 val_mae: 0.49752
epoch: 25 epoch time[sec]: 1 train loss: 0.4418 val loss: 1.0745 val_rmse: 1.03658 val_mae: 0.56204
epoch: 26 epoch time[sec]: 1 train loss: 0.3735 val loss: 1.5351 val_rmse: 1.23899 val_mae: 0.71568
epoch: 27 epoch time[sec]: 1 train loss: 0.4474 val loss: 1.1726 val_rmse: 1.08285 val_mae: 0.59331
epoch: 28 epoch time[sec]: 1 train loss: 0.4119 val loss: 2.5204 val_rmse: 1.58757 val_mae: 0.93299
epoch: 29 epoch time[sec]: 1 train loss: 0.5752 val loss: 0.9867 val_rmse: 0.99332 val_mae: 0.55090
epoch: 30 epoch time[sec]: 1 train loss: 0.3881 val loss: 0.9181 val_rmse: 0.95816 val_mae: 0.57685
epoch: 31 epoch time[sec]: 1 train loss: 0.3227 val loss: 1.1632 val_rmse: 1.07851 val_mae: 0.59697
epoch: 32 epoch time[sec]: 1 train loss: 0.4059 val loss: 0.7456 val_rmse: 0.86350 val_mae: 0.51384
epoch: 33 epoch time[sec]: 1 train loss: 0.3700 val loss: 0.4349 val_rmse: 0.65946 val_mae: 0.36350
epoch: 34 epoch time[sec]: 1 train loss: 0.2653 val loss: 0.5030 val_rmse: 0.70920 val_mae: 0.42115
epoch: 35 epoch time[sec]: 1 train loss: 0.2663 val loss: 0.5556 val_rmse: 0.74541 val_mae: 0.39126
epoch: 36 epoch time[sec]: 1 train loss: 0.2956 val loss: 0.4150 val_rmse: 0.64422 val_mae: 0.37835
epoch: 37 epoch time[sec]: 1 train loss: 0.2606 val loss: 0.3849 val_rmse: 0.62038 val_mae: 0.36641
epoch: 38 epoch time[sec]: 1 train loss: 0.2569 val loss: 0.4467 val_rmse: 0.66835 val_mae: 0.35664
epoch: 39 epoch time[sec]: 1 train loss: 0.2712 val loss: 0.6237 val_rmse: 0.78972 val_mae: 0.40919
epoch: 40 epoch time[sec]: 1 train loss: 0.2585 val loss: 0.4085 val_rmse: 0.63916 val_mae: 0.37400
epoch: 41 epoch time[sec]: 1 train loss: 0.2806 val loss: 0.5592 val_rmse: 0.74777 val_mae: 0.42447
epoch: 42 epoch time[sec]: 1 train loss: 0.2215 val loss: 0.3250 val_rmse: 0.57006 val_mae: 0.30865
epoch: 43 epoch time[sec]: 1 train loss: 0.2627 val loss: 0.2415 val_rmse: 0.49140 val_mae: 0.26592
epoch: 44 epoch time[sec]: 1 train loss: 0.2536 val loss: 0.3004 val_rmse: 0.54807 val_mae: 0.30688
epoch: 45 epoch time[sec]: 1 train loss: 0.2531 val loss: 0.2808 val_rmse: 0.52989 val_mae: 0.30597
epoch: 46 epoch time[sec]: 1 train loss: 0.2785 val loss: 0.8624 val_rmse: 0.92864 val_mae: 0.49453
epoch: 47 epoch time[sec]: 1 train loss: 0.2600 val loss: 0.6742 val_rmse: 0.82110 val_mae: 0.47749
epoch: 48 epoch time[sec]: 1 train loss: 0.3157 val loss: 0.3889 val_rmse: 0.62361 val_mae: 0.34720
epoch: 49 epoch time[sec]: 1 train loss: 0.2532 val loss: 0.4986 val_rmse: 0.70615 val_mae: 0.38780
/home/kemove/anaconda3/envs/il/lib/python3.9/site-packages/pysensing/acoustic/inference/training/AcousticPose_utils/libs/dataset.py:195: FutureWarning: DataFrame.fillna with 'method' is deprecated and will raise in a future version. Use obj.ffill() or obj.bfill() instead.
self.df[self.df["sound_length"] == sound_length]
---------- Start evaluation for test data ----------
loss: 0.24147 RMSE: 0.49 MAE: 0.27 Acc: 0.86, 0.96, 0.98, 0.99
arm RMSE: 0.64 arm MAE: 0.38 Acc: 0.79, 0.95, 0.98, 0.99
leg RMSE: 0.40 leg MAE: 0.22 Acc: 0.93, 0.98, 0.99, 0.99
body RMSE: 0.33 body MAE: 0.16 Acc: 0.94, 0.99, 1.00, 1.00
Done.
Load the Wipose_LSTM model¶
# Method 1
hpe_model = Wipose_LSTM(in_cha=4,out_cha=63).to(device)
# model_path = 'path to trained model'
# state_dict = torch.load(model_path,weights_only=True)
# Method 2
hpe_model = load_hpe_model('wipose',pretrained=True,task='subject8').to(device)
/home/kemove/anaconda3/envs/il/lib/python3.9/site-packages/torch/nn/modules/rnn.py:82: UserWarning: dropout option adds dropout after all but last recurrent layer, so non-zero dropout expects num_layers greater than 1, but got dropout=0.1 and num_layers=1
warnings.warn("dropout option adds dropout after all but last "
Load the data¶
csv = './data/hpe_dataset/csv/pose_regression_timeseries_subject_8/test.csv' # The path contains the samosa dataset
hpe_testdataset = SoundPoseLSTMDataset(csv,sound_length=2400,input_feature='raw',mean=np.array(get_raw_mean()).astype("float32"),std=np.array(get_raw_std()).astype("float32"))
index = 0 # Randomly select an index
sample= hpe_testdataset.__getitem__(index)
Model inference¶
# Method 1
hpe_model.eval()
predicted_result = hpe_model(sample['sound'].unsqueeze(0).float().to(device))
vis_images = make_images(sample['targets'],predicted_result.cpu().detach().squeeze(0))
#Method 2
from pysensing.acoustic.inference.predict import *
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
predicted_result = hpe_predict(sample['sound'],'SoundPoseLSTMDataset',hpe_model, device=device)
vis_images = make_images(sample['targets'].numpy(),predicted_result.cpu().detach().numpy().squeeze(0))
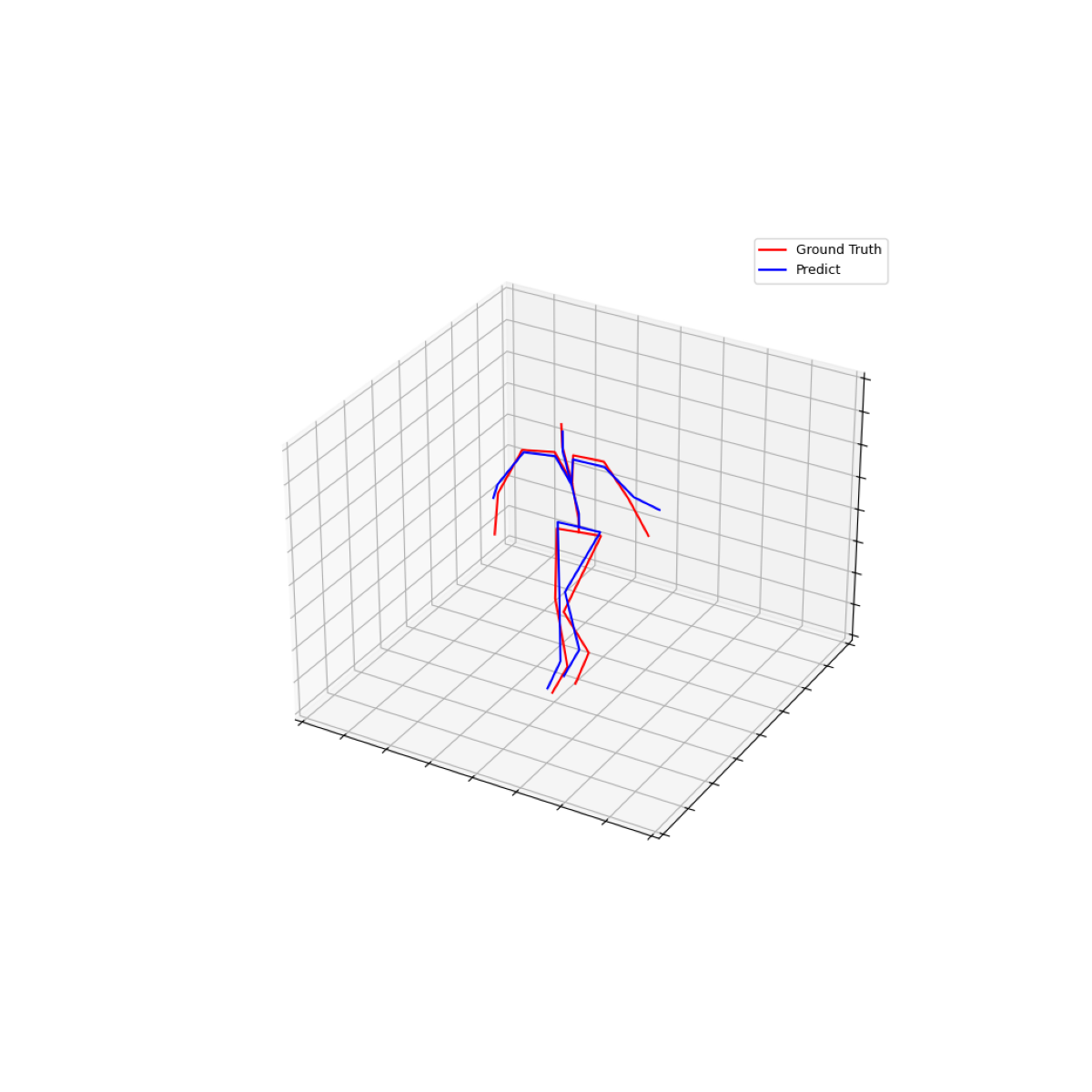
seq_num = 2
fig = plt.figure(figsize=(12, 12))
plt.imshow(vis_images[seq_num]['img'])
plt.axis('off')
plt.show()
Model embedding¶
from pysensing.acoustic.inference.embedding import *
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
sample_embedding = hpe_embedding(sample['sound'],'SoundPoseLSTMDataset',hpe_model, device=device)
And that’s it. We’re done with our acoustic humna pose estimation tutorials. Thanks for reading.
Total running time of the script: (3 minutes 10.114 seconds)
