Note
Go to the end to download the full example code.
Acoustic Preprocssing.Transfrom Tutorial¶
!pip install pysensing
In this tutorial, we will be implementing a simple acoustic.preprocessing.transform
import torch
import torchaudio
import matplotlib.pyplot as plt
import librosa
import pysensing.acoustic.preprocessing.transform as transform
Load the audio¶
First, the example audio is loaded
# Define the plot function
def plot_wave(waveform,sample_rate):
plt.figure(figsize=(10, 5))
plt.plot(waveform.t().numpy())
plt.title('Waveform')
plt.xlabel('Sample')
plt.ylabel('Amplitude')
plt.tight_layout()
plt.show()
def plot_spec(waveform,sample_rate,feature_extractor,title):
specgram = torch.abs(feature_extractor(waveform))
# specgram = transform.aplitude2db()(specgram)
plt.figure(figsize=(10,5))
plt.imshow(specgram[0].squeeze().numpy(), aspect='auto', origin='lower', cmap='inferno', extent=[0, waveform.size(1) / sample_rate, 0, sample_rate / 2])
plt.title(title)
plt.ylim(0,5000)
plt.xlabel('Time (s)')
plt.ylabel('Frequency (Hz)')
# Load the data
# Load the data
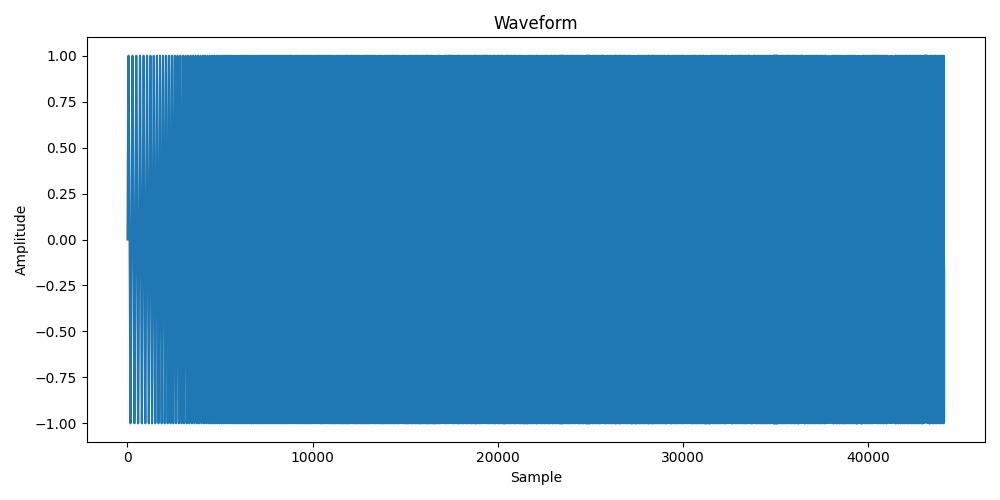
waveform, sample_rate = torchaudio.load('example_data/example_audio.wav')
plot_wave(waveform,sample_rate)
1. STFT¶
stft_trans = transform.stft(n_fft=2048,hop_length=1024)
plot_spec(waveform,sample_rate,stft_trans,'STFT')
2. ISTFT¶
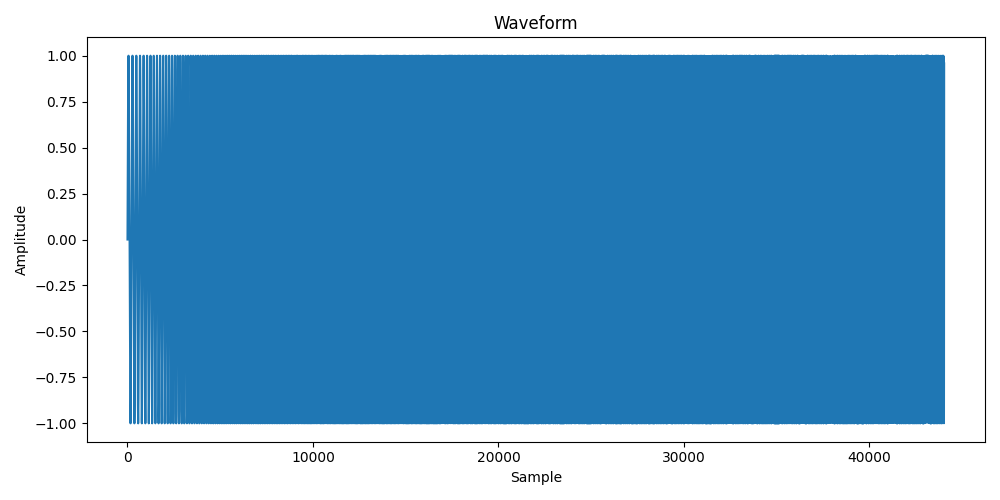
stft_result = stft_trans(waveform)
ifft_trans = transform.istft(n_fft=2048,hop_length=1024,return_complex=False)
ifft_result = ifft_trans(stft_result)
plot_wave(ifft_result,sample_rate)
3. Spectrogram¶
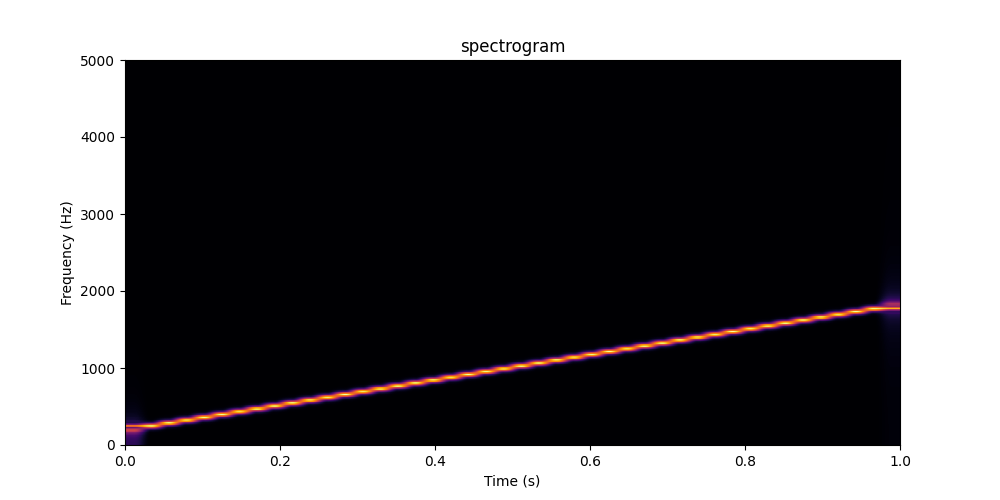
spectrogram_trans = transform.spectrogram(n_fft=2048,hop_length=1024,power=None)
plot_spec(waveform,sample_rate,spectrogram_trans,'spectrogram')
4. Inversespectrogram¶
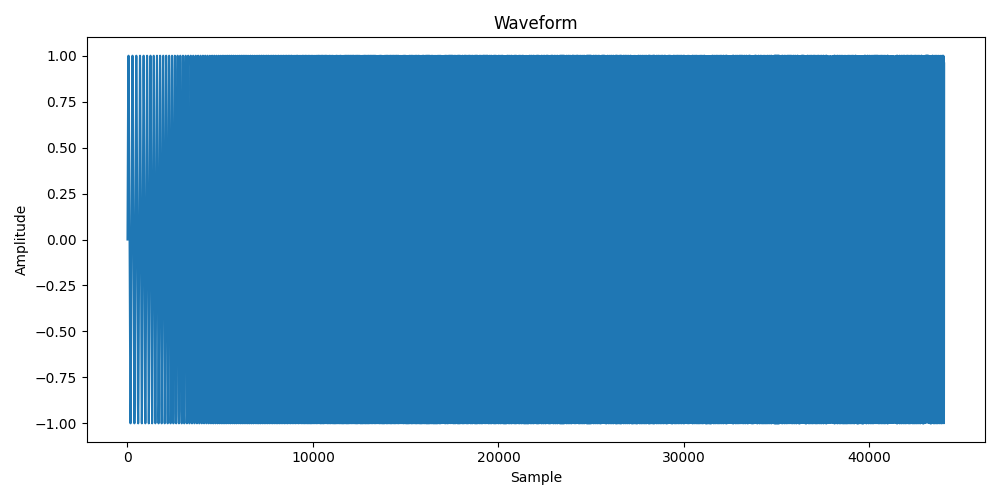
spectrogram_result = spectrogram_trans(waveform)
ispec_trans = transform.inversespectrogram(n_fft=2048,hop_length=1024)
ispec_result = ispec_trans(spectrogram_result)
plot_wave(ispec_result,sample_rate)
5. Melspectrogram¶
def plot_melspectrogram(specgram, title=None, ylabel="freq_bin", ax=None):
if ax is None:
_, ax = plt.subplots(1, 1,figsize=(10,5))
if title is not None:
ax.set_title(title)
ax.set_ylabel(ylabel)
ax.imshow(librosa.power_to_db(specgram), origin="lower", aspect="auto", interpolation="nearest")
melspectrogram_trans = transform.melspectrogram(sample_rate=sample_rate,n_fft=2048,hop_length=1024)
melspec = melspectrogram_trans(waveform)[0].numpy()
plot_melspectrogram(melspec,'melspectrogram')
And that’s it. We’re done with our acoustic preprocessing tutorials. Thanks for reading.
Total running time of the script: (0 minutes 0.915 seconds)
