Note
Go to the end to download the full example code.
Acoustic augmentation.spectrogram_aug Tutorial¶
!pip install pysensing
In this tutorial, we will be implementing a simple acoustic.augmentation.spectrogram_aug
import torch
import librosa
import numpy as np
import torchaudio
import matplotlib.pyplot as plt
import sys
import pysensing.acoustic.augmentation.spectrogram_aug as spec_aug
import pysensing.acoustic.preprocessing.transform as transform
Load the audio¶
First, the example audio is loaded
# Define the plot function
def plot(specs, titles):
maxlen = max(spec.shape[-1] for spec in specs)
def plot_spec(ax, spec, title):
ax.set_title(title)
ax.imshow(spec, origin="lower", aspect="auto")
ax.set_xlim(0, maxlen)
num_specs = len(specs)
fig, axes = plt.subplots(num_specs, 1,figsize=(12,8))
if num_specs == 1:
axes = [axes]
for ax, spec, title in zip(axes, specs, titles):
plot_spec(ax, spec[0].float(), title)
fig.tight_layout()
plt.show()
# Load the data
waveform, sample_rate = torchaudio.load('example_data/example_audio.wav')
spectrogram = transform.spectrogram()(waveform)
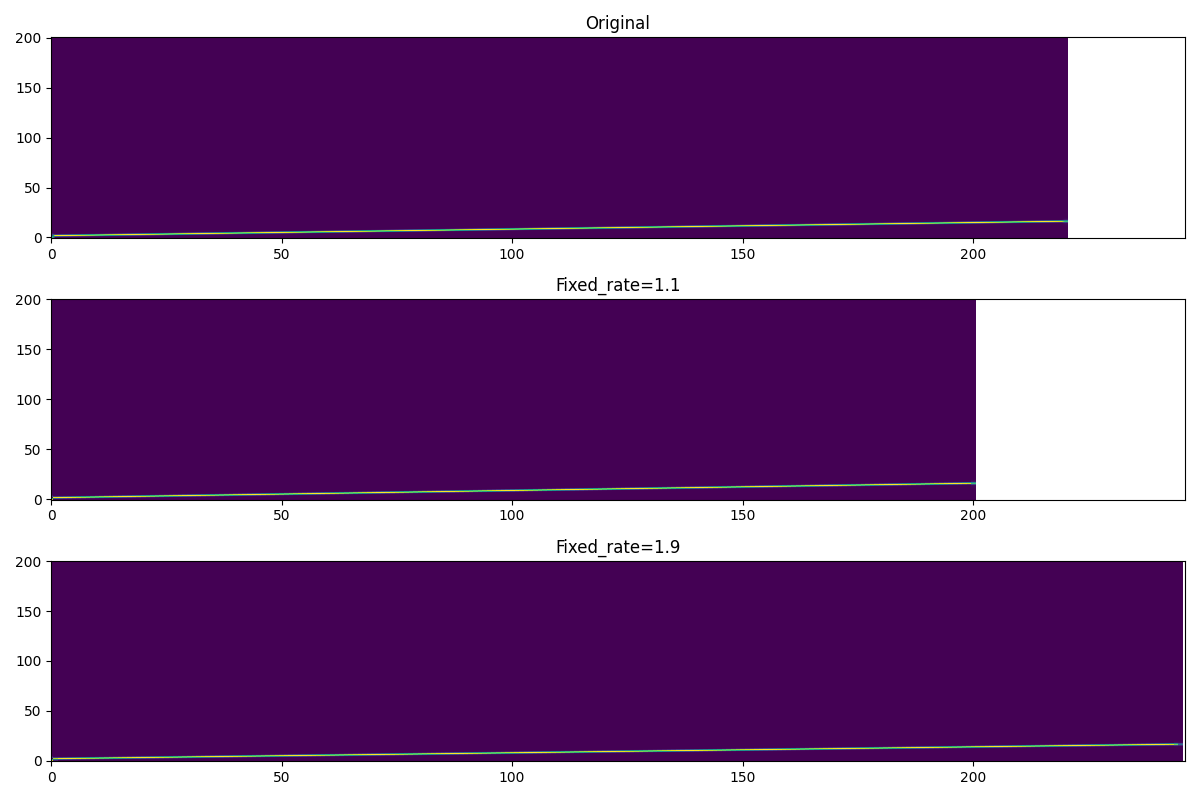
1. Timestretch¶
# Define timestretch with different fixed_rate
timestretch_compress = spec_aug.timestretch(fixed_rate=1.1)
timestretch_extend = spec_aug.timestretch(fixed_rate=0.9)
# Do timestretch to the input spectrogram
spectrogram_com = timestretch_compress(spectrogram)
spectrogram_ext = timestretch_extend(spectrogram)
# Plotting
plot([spectrogram,spectrogram_com,spectrogram_ext],['Original','Fixed_rate=1.1','Fixed_rate=1.9'])
/home/kemove/yyz/av-gihub/tutorials/acoustic_source/acoustic_spectrogram_aug_tutorial.py:40: UserWarning: Casting complex values to real discards the imaginary part (Triggered internally at ../aten/src/ATen/native/Copy.cpp:299.)
plot_spec(ax, spec[0].float(), title)
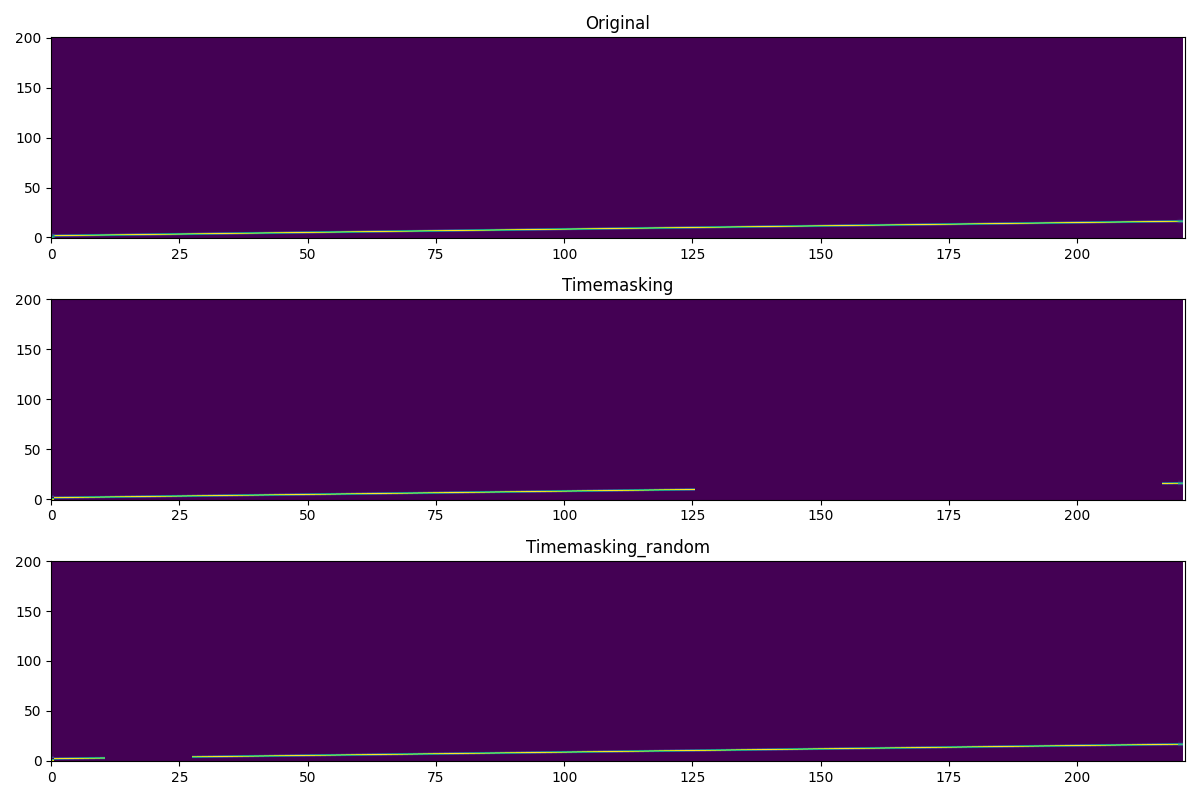
2. Timemasking¶
timemasking_trans = spec_aug.timemasking(200)
timemasking_random_trans = spec_aug.timemasking(200,p=0.5)
timemask_spec = timemasking_trans(spectrogram)
timemask_r_spec = timemasking_random_trans(spectrogram)
plot([spectrogram,timemask_spec,timemask_r_spec],['Original','Timemasking','Timemasking_random'])
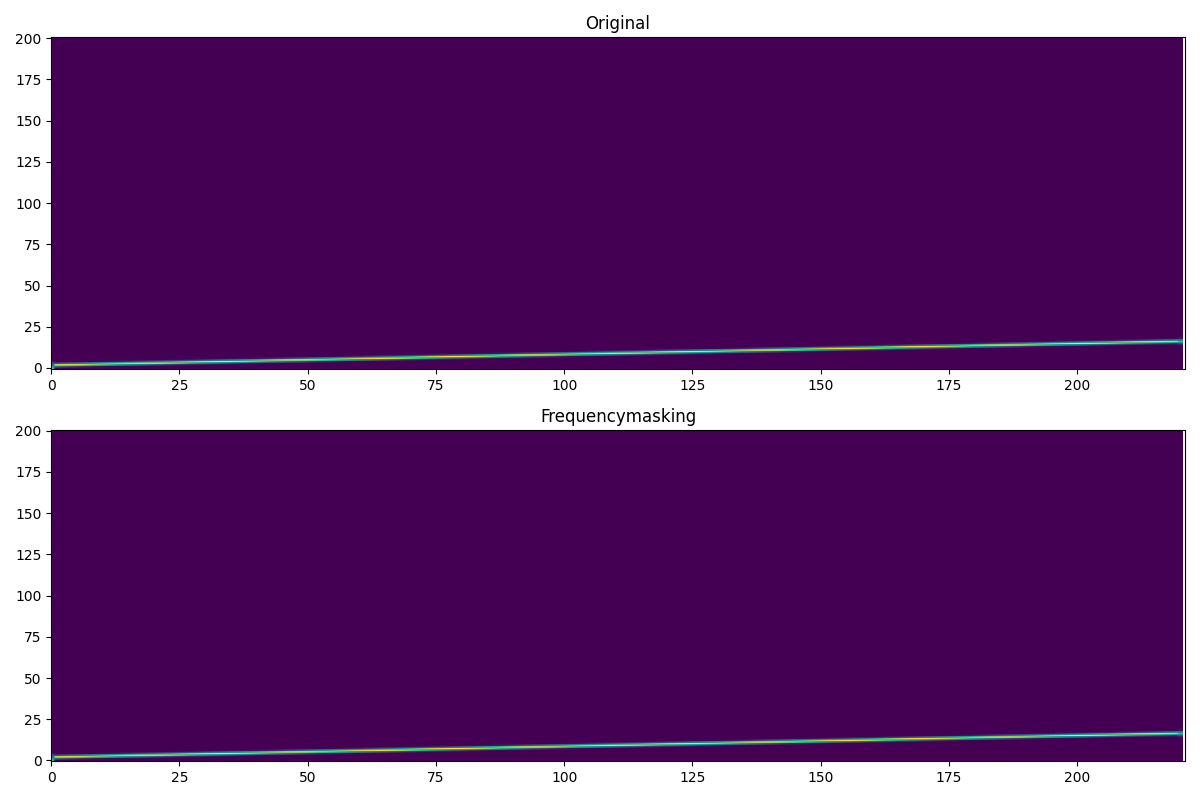
3. Frequecymasking¶
frequencymasking_trans = spec_aug.frequencymasking(400)
frequencymask_spec = frequencymasking_trans(spectrogram)
plot([spectrogram,frequencymask_spec],['Original','Frequencymasking'])
And that’s it. We’re done with our acoustic augmentation.signal_aug tutorials. Thanks for reading.
Total running time of the script: (0 minutes 0.429 seconds)
